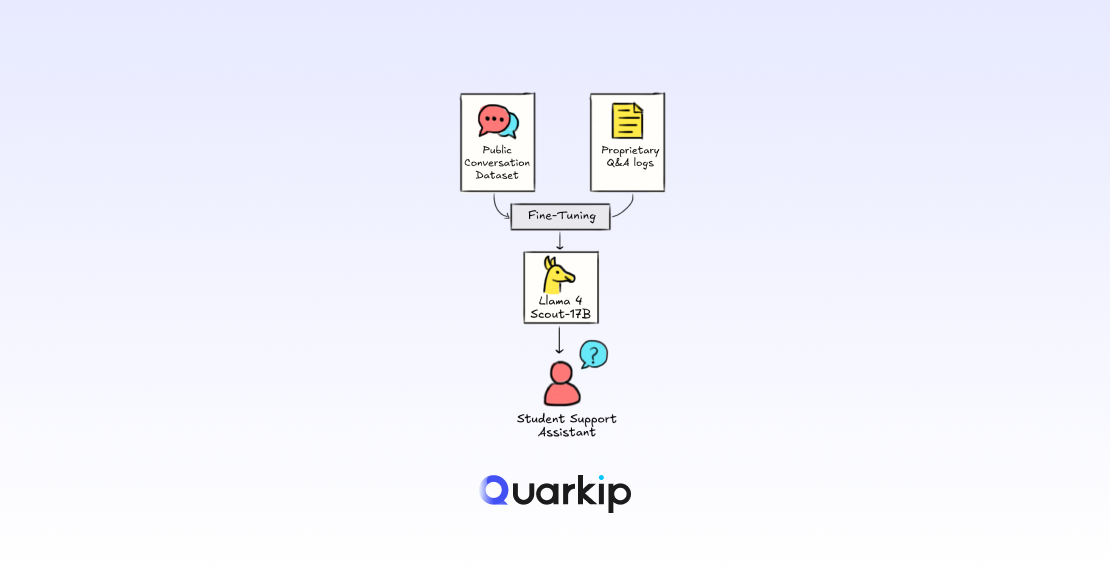
Many teams fine-tune Llama 4 and expect immediate improvements.
However, results often feel underwhelming. Accuracy barely moves. Outputs sound generic. Domain knowledge still feels outdated.
In most cases, the problem is not the model or the training code.
Instead, the real bottleneck lies in the data itself—especially how recent, relevant, and structured it is.
This article focuses on why fresh web data changes outcomes and how teams actually use it to unlock better results.
Why Data Freshness Matters More Than Most Hyperparameters
Llama 4 ships with strong general reasoning capabilities.
What it lacks—by design—is awareness of fast-changing real-world information.
Fresh web data introduces:
- New terminology and evolving language patterns
- Updated facts, products, APIs, and workflows
- Current user intent rather than historical assumptions
As a result, models trained on stale corpora often answer correctly in theory but fail in practice.
The Hidden Gap Between “Web Data” and “Useful Web Data”
Many teams assume that collecting web data automatically improves performance.
In reality, raw web data is noisy, inconsistent, and often misleading.
Common problems include:
- SEO-driven filler content
- Duplicate or near-duplicate pages
- Outdated tutorials that still rank well
- Opinionated posts disguised as documentation
Without careful filtering, fresh data can actually degrade model behavior.
Where Fine-Tuning with Fresh Data Delivers the Biggest Gains
Not every task benefits equally from recent data.
However, strong improvements consistently appear in areas such as:
- Developer tooling and frameworks
- SaaS workflows and product documentation
- Market-specific terminology
- Operational procedures that change quarterly
In these domains, freshness directly correlates with user trust and perceived intelligence.
Why “More Data” Is Often the Wrong Strategy
It’s tempting to scrape more pages and scale training runs.
Yet teams frequently see diminishing returns—or even regressions.
This happens because:
- Low-quality samples overwhelm signal
- Inconsistent writing styles confuse the model
- Conflicting sources dilute learned patterns
Instead of volume, data alignment becomes the decisive factor.
A Practical Mental Model for Using Fresh Web Data
Successful teams usually follow a three-layer approach:
1. Intent-Driven Collection
They collect content based on user intent, not keywords alone.
For example, problem-solving discussions often outperform polished landing pages.
2. Structural Normalization
They normalize formats before training:
- Strip navigation and ads
- Standardize headings and code blocks
- Preserve context rather than isolated snippets
This step dramatically improves training efficiency.
3. Controlled Exposure During Fine-Tuning
Rather than flooding the model, teams expose fresh data gradually.
This prevents overfitting to short-lived trends.
Fine-Tuning vs. Continual Updating: A Strategic Choice
Fresh web data raises an important question:
Should you fine-tune once—or update continuously?
- Fine-tuning works well for stable domains with periodic updates
- Continual updates suit fast-moving products or APIs
Choosing the wrong strategy often explains disappointing results.
Evaluation: Why Offline Benchmarks Don’t Tell the Full Story
Many teams rely on offline metrics to validate improvements.
However, these benchmarks rarely reflect real user interaction.
Better signals include:
- Reduced hallucinations in live prompts
- Faster task completion
- Higher user trust in domain answers
Fresh data shows its value most clearly in production behavior, not leaderboard scores.
Common Mistakes Teams Make
Across projects, the same issues appear repeatedly:
- Treating freshness as a one-time fix
- Ignoring source credibility
- Mixing incompatible domains in one dataset
- Evaluating only on synthetic prompts
Avoiding these mistakes often matters more than model size.
Final Thoughts: Data Is the Long-Term Advantage
Llama 4 provides a strong foundation.
Fresh web data determines whether that foundation supports real-world use cases—or collapses under them.
Teams that treat data as a living asset, not a static input, consistently achieve better results than those chasing architectural tweaks.